
Original post
Update 1
Update 2
Update 3
In previous posts, I’ve presented on the range of Open workout placings athletes have and its impact on CrossFit Games Regional qualification. Here, I’ve produced some simple, linear regressions that try to predict overall place during an Open competition from knowledge of one to four individual workout placings.
The Question
A question one might ask is: I am currently ranked at 100th overall after 14.1 and 14.2, how well does this placing predict my ranking by the end of the Open competition?
Short answer: It doesn’t.
Long answer: Not very well. Let’s demonstrate what I mean with another set of plots.
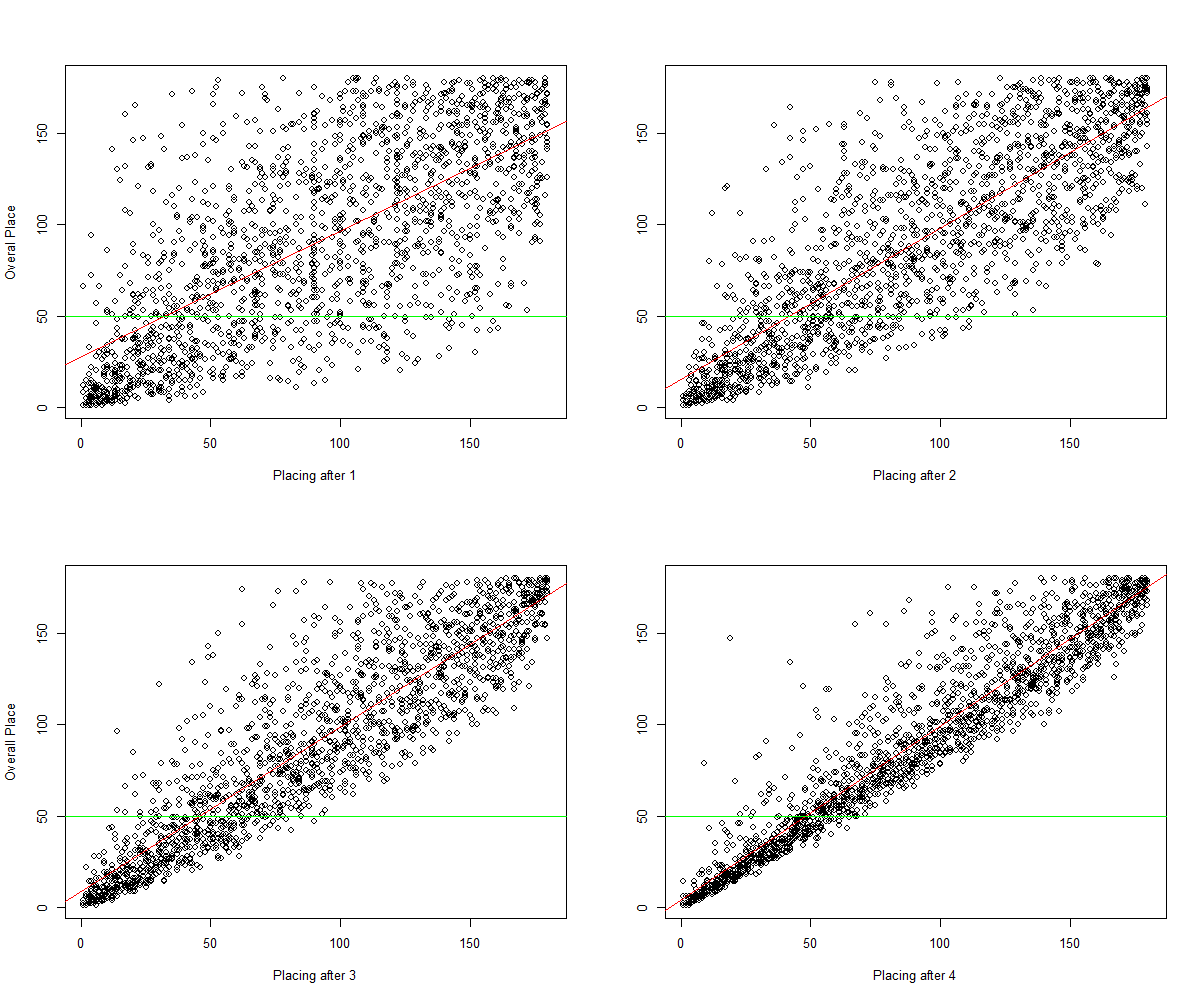
Click on the image to make it bigger. Figure 1 shows four regressions performed after plotting an individual’s overall placing after 1, 2, 3, or 4 Open workouts against her finishing, overall place.
{kind=link}
Let’s look at the top left plot. An athlete performs the first workout of the year, and she scores 100th. This plot says: there is no way we can accurately predict how she will finish. While the regression is statistically significant, the r-squared is 0.48, which isn’t very high. Just look at all the variation!
Now take a look at the top-right plot. After two workouts, the data tighten (this is partially an artifact of how I produced these data) and are better predicted by the red regression, but there is still a huge amount of variation that doesn’t fall directly on that red line. If all the points fall on that line, it suggest that we can easily predict overall place from placings after a given number of workouts. The r-squared is increased to 0.67, but someone ranked 100th after two workouts still has a good chance at qualifying for Regionals – that is, there are still a good number of points falling below the green line where x = 100.
Notice that the data get closer to the red line (the regression) as more workouts are added. Makes sense: if you’re ranked 100th after four workouts, it’s pretty unlikely that the 5th workout will swing you up or down too much in the overall rankings. But it does happen.
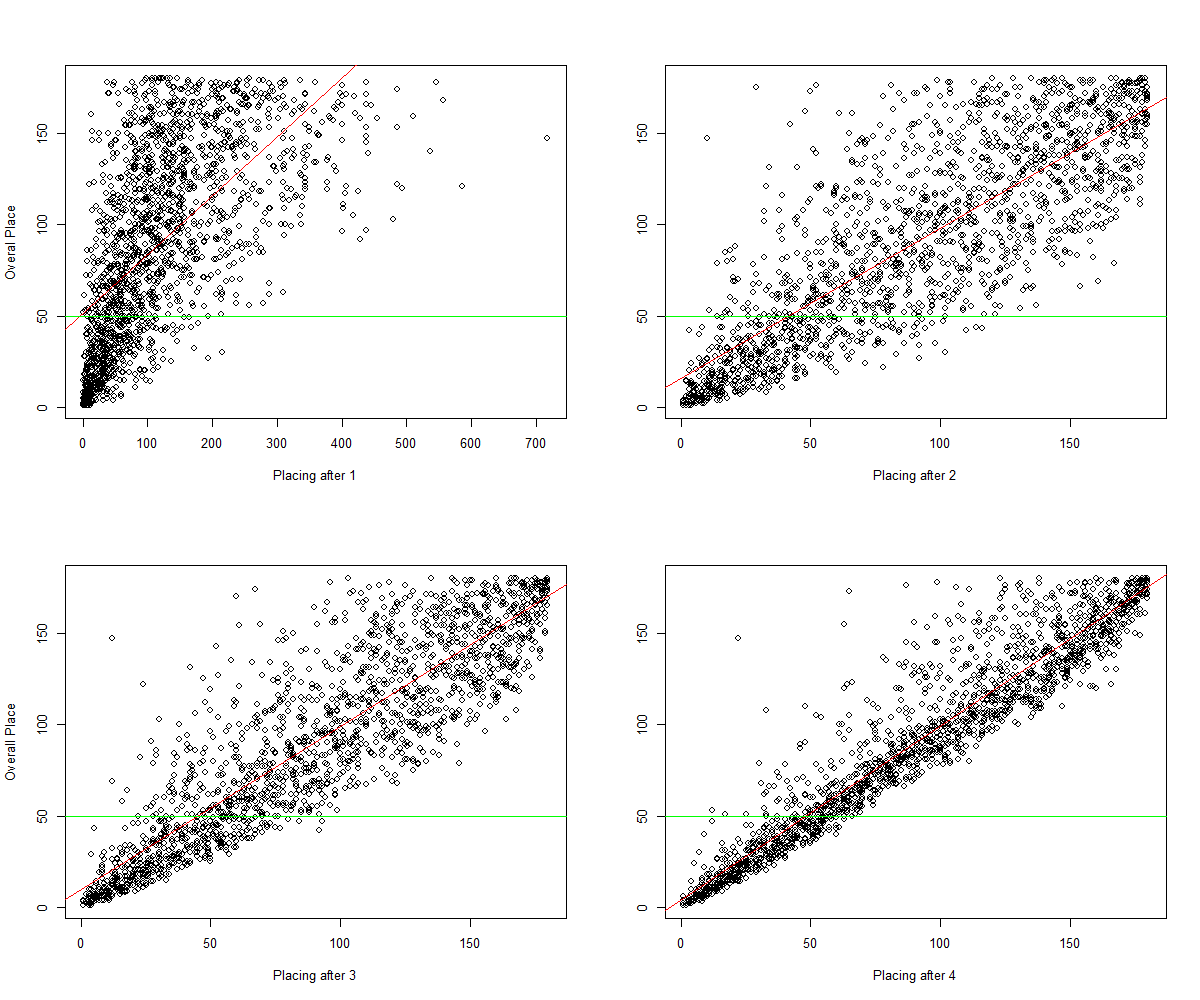
I generated the mid-Open rankings (overall placings after 1, 2, 3, and 4 workouts) with the sample() function in R, which gives me some ‘randomness’. For instance, sample() was used to randomly select two workout-specific placings of the total five for a given athlete and given Open competition. Thus, ‘Placing after 2 workouts’ is not an athletes actual placing after 12.1 and 12.2, it’s a placing I calculated after drawing, at random, 2 of the 5 workouts for that athlete in 2012, and them ranking them with another R function (rank()). A problem with this approach: maximum rankings are capped at 180 for all the plots, but an athlete could have been ranked much higher in the actual Open. Figure 2 is an example where the actual workout placings are considered and used to predict overall placing. This is the same data as the top-left plot in Figure 1, but I haven’t ranked it myself. The data don’t even appear to be linear (the data look to be curving upwards), and the r-squared of the regression has fallen to 0.38. I can’t do this with the other three plots without copying the data from the Games webpage again.
There are other weird artifacts that I’ve introduced with these data, but I think the problems cause my results and conclusions to be conservative. That is, if I had all the data, there would be more variation and unpredictability… If you’re interested in knowing how, comment or ask.
Bigger picture
This post presents more evidence that watching rankings closely early in an Open competition is of little value. Sure, it’s not going to be easy or likely that one will qualify for Regionals after hitting >300th place in a single workout, and it will be harder if you’re ranked 150th after three workouts… but it’s been done before. This is, again, a reason to stay positive, and to strive to be better.